The model is the brain of the intelligent agent, responsible for intelligent agent, processing all input and output data to execute tasks such as text analysis, image recognition, and complex reasoning. With customizable interfaces and multiple integration options, CAMEL AI enables rapid development with leading LLMs.
Explore the Code: Check out our Colab Notebook for a hands-on demonstration.
CAMEL supports a wide range of models, including OpenAI’s GPT series, Meta’s Llama models, DeepSeek models (R1 and other variants), and more. The table below lists all supported model platforms:
| Model Platform | Model Type(s) |
|---|---|
| OpenAI | gpt-4.5-preview, gpt-4o, gpt-4o-mini, o1, o1-preview, o1-mini, o3-mini, gpt-4-turbo, gpt-4, gpt-3.5-turbo |
| Azure OpenAI | gpt-4o, gpt-4-turbo, gpt-4, gpt-3.5-turbo |
| Mistral AI | mistral-large-latest, pixtral-12b-2409, ministral-8b-latest, ministral-3b-latest, open-mistral-nemo, codestral-latest, open-mistral-7b, open-mixtral-8x7b, open-mixtral-8x22b, open-codestral-mamba |
| Moonshot | moonshot-v1-8k, moonshot-v1-32k, moonshot-v1-128k |
| Anthropic | claude-2.1, claude-2.0, claude-instant-1.2, claude-3-opus-latest, claude-3-sonnet-20240229, claude-3-haiku-20240307, claude-3-5-sonnet-latest, claude-3-5-haiku-latest |
| Gemini | gemini-2.0-flash-exp, gemini-1.5-pro, gemini-1.5-flash, gemini-exp-1114 |
| Lingyiwanwu | yi-lightning, yi-large, yi-medium, yi-large-turbo, yi-vision, yi-medium-200k, yi-spark, yi-large-rag, yi-large-fc |
| Qwen | qwq-32b-preview, qwen-max, qwen-plus, qwen-turbo, qwen-long, qwen-vl-max, qwen-vl-plus, qwen-math-plus, qwen-math-turbo, qwen-coder-turbo, qwen2.5-coder-32b-instruct, qwen2.5-72b-instruct, qwen2.5-32b-instruct, qwen2.5-14b-instruct |
| DeepSeek | deepseek-chat, deepseek-reasoner |
| ZhipuAI | glm-4, glm-4v, glm-4v-flash, glm-4v-plus-0111, glm-4-plus, glm-4-air, glm-4-air-0111, glm-4-airx, glm-4-long, glm-4-flashx, glm-zero-preview, glm-4-flash, glm-3-turbo |
| InternLM | internlm3-latest, internlm3-8b-instruct, internlm2.5-latest, internlm2-pro-chat |
| Reka | reka-core, reka-flash, reka-edge |
| COHERE | command-r-plus, command-r, command-light, command, command-nightly |
| GROQ | supported models |
| TOGETHER AI | supported models |
| SambaNova | supported models |
| Ollama | supported models |
| OpenRouter | supported models |
| PPIO | supported models |
| LiteLLM | supported models |
| vLLM | supported models |
| SGLANG | supported models |
| NVIDIA | supported models |
| AIML | supported models |
| ModelScope | supported models |
| AWS Bedrock | supported models |
Easily integrate your chosen model with CAMEL AI using straightforward API calls. For example, to use the gpt-4o-mini model:
If you want to use another model, you can simply change these three parameters:
model_platform,model_type,model_config_dict.
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
from camel.configs import ChatGPTConfig
from camel.messages import BaseMessage
from camel.agents import ChatAgent
# Define the model, here in this case we use gpt-4o-mini
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI,
model_type=ModelType.GPT_4O_MINI,
model_config_dict=ChatGPTConfig().as_dict(),
)
# Define an assistant message
system_msg = "You are a helpful assistant."
# Initialize the agent
ChatAgent(system_msg, model=model)And if you want to use an OpenAI-compatible API, you can replace the
modelwith the following code:
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="a-string-representing-the-model-type",
api_key=os.environ.get("OPENAI_COMPATIBILITY_API_KEY"),
url=os.environ.get("OPENAI_COMPATIBILITY_API_BASE_URL"),
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)CAMEL AI also supports local deployment of open-source LLMs. Choose the setup that suits your project:
- Download Ollama.
- After setting up Ollama, pick a model like Llama3 for your project:
ollama pull llama3- Create a
ModelFilesimilar the one below in your project directory. (Optional)
FROM llama3
# Set parameters
PARAMETER temperature 0.8
PARAMETER stop Result
# Sets a custom system message to specify the behavior of the chat assistant
# Leaving it blank for now.
SYSTEM """ """
- Create a script to get the base model (llama3) and create a custom model using the
ModelFileabove. Save this as a.shfile: (Optional)
#!/bin/zsh
# variables
model_name="llama3"
custom_model_name="camel-llama3"
#get the base model
ollama pull $model_name
#create the model file
ollama create $custom_model_name -f ./Llama3ModelFile
- Navigate to the directory where the script and
ModelFileare located and run the script. Enjoy your Llama3 model, enhanced by CAMEL's excellent agents.
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType
ollama_model = ModelFactory.create(
model_platform=ModelPlatformType.OLLAMA,
model_type="llama3",
url="http://localhost:11434/v1", # Optional
model_config_dict={"temperature": 0.4},
)
agent_sys_msg = "You are a helpful assistant."
agent = ChatAgent(agent_sys_msg, model=ollama_model, token_limit=4096)
user_msg = "Say hi to CAMEL"
assistant_response = agent.step(user_msg)
print(assistant_response.msg.content)Install vLLM first.
After setting up vLLM, start an OpenAI compatible server for example by:
python -m vllm.entrypoints.openai.api_server --model microsoft/Phi-3-mini-4k-instruct --api-key vllm --dtype bfloat16
Create and run following script (more details please refer to this example):
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType
vllm_model = ModelFactory.create(
model_platform=ModelPlatformType.VLLM,
model_type="microsoft/Phi-3-mini-4k-instruct",
url="http://localhost:8000/v1", # Optional
model_config_dict={"temperature": 0.0}, # Optional
)
agent_sys_msg = "You are a helpful assistant."
agent = ChatAgent(agent_sys_msg, model=vllm_model, token_limit=4096)
user_msg = "Say hi to CAMEL AI"
assistant_response = agent.step(user_msg)
print(assistant_response.msg.content)Install SGLang first.
Create and run following script (more details please refer to this example):
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType
sglang_model = ModelFactory.create(
model_platform=ModelPlatformType.SGLANG,
model_type="meta-llama/Llama-3.2-1B-Instruct",
model_config_dict={"temperature": 0.0},
api_key="sglang",
)
agent_sys_msg = "You are a helpful assistant."
agent = ChatAgent(agent_sys_msg, model=sglang_model, token_limit=4096)
user_msg = "Say hi to CAMEL AI"
assistant_response = agent.step(user_msg)
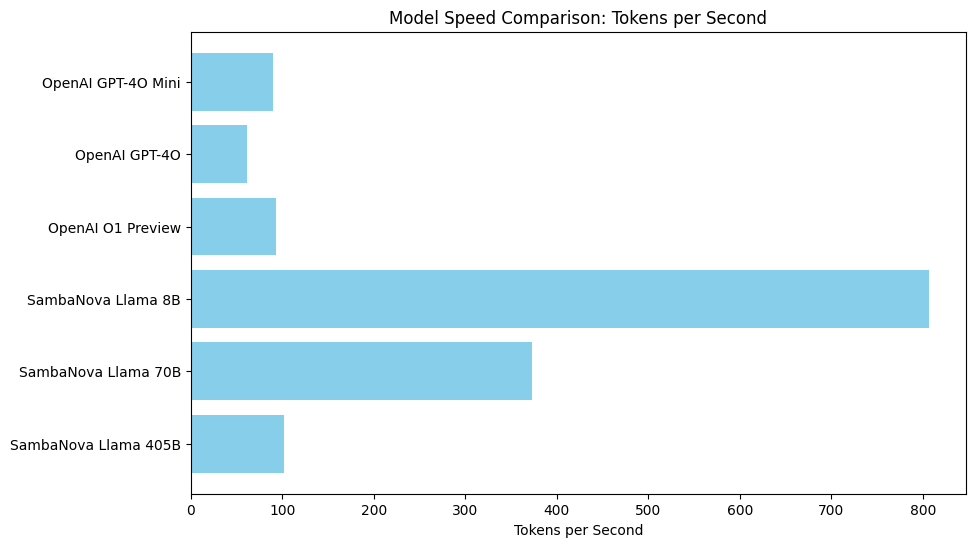
print(assistant_response.msg.content)Performance is critical for interactive AI applications. CAMEL-AI benchmarks tokens processed per second across various models:
In this notebook, we compared several models, including OpenAI’s GPT-4O Mini, GPT-4O, O1 Preview, and SambaNova's Llama series, by measuring the number of tokens each model processes per second.
Key Insights: Smaller models like SambaNova’s Llama 8B and OpenAI's GPT-4O Mini typically offer faster responses. Larger models like SambaNova’s Llama 405B, while more powerful, tend to generate output more slowly due to their complexity. OpenAI models demonstrate relatively consistent performance, while SambaNova's Llama 8B significantly outperforms others in speed. The chart below illustrates the tokens per second achieved by each model during our tests:
For local inference, we conducted a straightforward comparison locally between vLLM and SGLang. SGLang demonstrated superior performance, with meta-llama/Llama-3.2-1B-Instruct reaching a peak speed of 220.98 tokens per second, compared to vLLM, which capped at 107.2 tokens per second.
You've now learned how to integrate various models into CAMEL AI.
Next, check out our guide covering basics of creating and converting messages with BaseMessage.