| title | keywords | description | |||
|---|---|---|---|---|---|
AI内容安全 |
|
阿里云内容安全检测 |
通过对接阿里云内容安全检测大模型的输入输出,保障AI应用内容合法合规。
插件执行阶段:默认阶段
插件执行优先级:300
| Name | Type | Requirement | Default | Description |
|---|---|---|---|---|
serviceName |
string | requried | - | 服务名 |
servicePort |
string | requried | - | 服务端口 |
serviceHost |
string | requried | - | 阿里云内容安全endpoint的域名 |
accessKey |
string | requried | - | 阿里云AK |
secretKey |
string | requried | - | 阿里云SK |
checkRequest |
bool | optional | false | 检查提问内容是否合规 |
checkResponse |
bool | optional | false | 检查大模型的回答内容是否合规,生效时会使流式响应变为非流式 |
requestCheckService |
string | optional | llm_query_moderation | 指定阿里云内容安全用于检测输入内容的服务 |
responseCheckService |
string | optional | llm_response_moderation | 指定阿里云内容安全用于检测输出内容的服务 |
requestContentJsonPath |
string | optional | [email protected] |
指定要检测内容在请求body中的jsonpath |
responseContentJsonPath |
string | optional | choices.0.message.content |
指定要检测内容在响应body中的jsonpath |
responseStreamContentJsonPath |
string | optional | choices.0.delta.content |
指定要检测内容在流式响应body中的jsonpath |
denyCode |
int | optional | 200 | 指定内容非法时的响应状态码 |
denyMessage |
string | optional | openai格式的流式/非流式响应 | 指定内容非法时的响应内容 |
protocol |
string | optional | openai | 协议格式,非openai协议填original |
riskLevelBar |
string | optional | high | 拦截风险等级,取值为 max, high, medium, low |
timeout |
int | optional | 2000 | 调用内容安全服务时的超时时间 |
补充说明一下 denyMessage,对非法请求的处理逻辑为:
- 如果配置了
denyMessage,返回内容为denyMessage配置内容,格式为openai格式的流式/非流式响应 - 如果没有配置
denyMessage,优先返回阿里云内容安全的建议回答,格式为openai格式的流式/非流式响应 - 如果阿里云内容安全未返回建议的回答,返回内容为内置的兜底回答,内容为
"很抱歉,我无法回答您的问题",格式为openai格式的流式/非流式响应
如果用户使用了非openai格式的协议,此时对非法请求的处理逻辑为:
- 如果配置了
denyMessage,返回用户配置的denyMessage内容,非流式响应 - 如果没有配置
denyMessage,优先返回阿里云内容安全的建议回答,非流式响应 - 如果阿里云内容安全未返回建议回答,返回内置的兜底回答,内容为
"很抱歉,我无法回答您的问题",非流式响应
补充说明一下 riskLevelBar 的四个等级:
max: 检测请求/响应内容,但是不会产生拦截行为high: 内容安全检测结果中风险等级为high时产生拦截medium: 内容安全检测结果中风险等级 >=medium时产生拦截low: 内容安全检测结果中风险等级 >=low时产生拦截
由于插件中需要调用阿里云内容安全服务,所以需要先创建一个DNS类型的服务,例如:
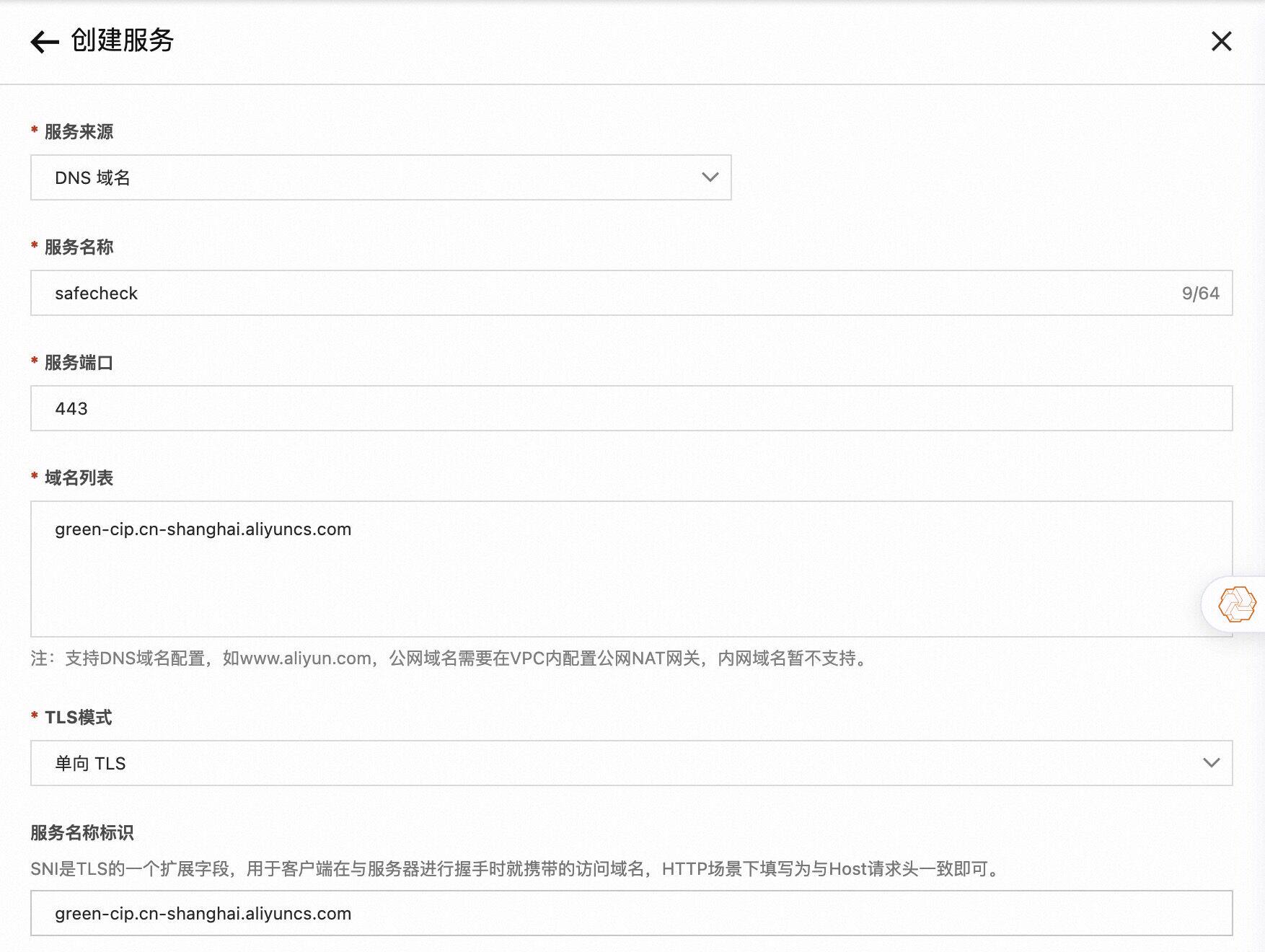
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: trueserviceName: safecheck.dns
servicePort: 443
serviceHost: green-cip.cn-shanghai.aliyuncs.com
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
checkResponse: true用户可能需要根据不同的场景配置不同的检测规则,该问题可通过为不同域名/路由/服务配置不同的内容安全检测服务实现。如下图所示,我们创建了一个名为 llm_query_moderation_01 的检测服务,其中的检测规则在 llm_query_moderation 之上做了一些改动:
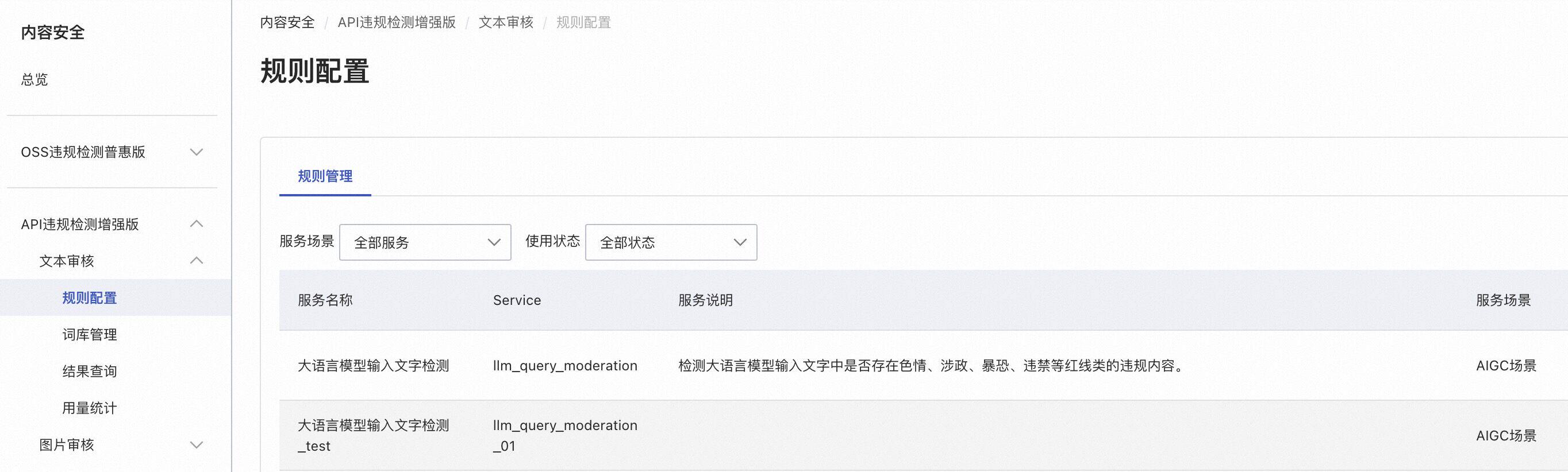
接下来在目标域名/路由/服务级别进行以下配置,指定使用我们自定义的 llm_query_moderation_01 中的规则进行检测:
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
requestCheckService: llm_query_moderation_01serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
checkResponse: true
requestContentJsonPath: "input.prompt"
responseContentJsonPath: "output.text"
denyCode: 200
denyMessage: "很抱歉,我无法回答您的问题"
protocol: originalai-security-guard 插件提供了以下监控指标:
ai_sec_request_deny: 请求内容安全检测失败请求数ai_sec_response_deny: 模型回答安全检测失败请求数
如果开启了链路追踪,ai-security-guard 插件会在请求 span 中添加以下 attributes:
ai_sec_risklabel: 表示请求命中的风险类型ai_sec_deny_phase: 表示请求被检测到风险的阶段(取值为request或者response)
curl http://localhost/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "这是一段非法内容"
}
]
}'请求内容会被发送到阿里云内容安全服务进行检测,如果请求内容检测结果为非法,网关将返回形如以下的回答:
{
"id": "chatcmpl-AAy3hK1dE4ODaegbGOMoC9VY4Sizv",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-4o-mini",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "作为一名人工智能助手,我不能提供涉及色情、暴力、政治等敏感话题的内容。如果您有其他相关问题,欢迎您提问。",
},
"logprobs": null,
"finish_reason": "stop"
}
]
}