File tree 7 files changed +11
-11
lines changed
7 files changed +11
-11
lines changed Original file line number Diff line number Diff line change 7070
7171如果公司预算充足对于新的服务器是可以考虑购买更好的 CPU,但是对于已经在使用的服务器,硬件优化的方式可能就不太适合了,于是就要从软件的方向来优化了。
7272
73- 软件的优化方向可以分层两种 ,一个是** 软件升级** ,一个是** 协议优化** 。
73+ 软件的优化方向可以分成两种 ,一个是** 软件升级** ,一个是** 协议优化** 。
7474
7575先说第一个软件升级,软件升级就是将正在使用的软件升级到最新版本,因为最新版本不仅提供了最新的特性,也优化了以前软件的问题或性能。比如:
7676
Original file line number Diff line number Diff line change @@ -87,7 +87,7 @@ TLS 协议是如何解决 HTTP 的风险的呢?
8787
8888这个密码套件看起来真让人头晕,好一大串,但是其实它是有固定格式和规范的。基本的形式是「** 密钥交换算法 + 签名算法 + 对称加密算法 + 摘要算法** 」,一般 WITH 单词前面有两个单词,第一个单词是约定密钥交换的算法,第二个单词是约定证书的验证算法。比如刚才的密码套件的意思就是:
8989
90- - 由于 WITH 单词只有一个 RSA,则说明握手时密钥交换算法和签名算法都是使用 RSA;
90+ - 由于 WITH 单词前只有一个 RSA,则说明握手时密钥交换算法和签名算法都是使用 RSA;
9191- 握手后的通信使用 AES 对称算法,密钥长度 128 位,分组模式是 GCM;
9292- 摘要算法 SHA256 用于消息认证和产生随机数;
9393
Original file line number Diff line number Diff line change @@ -581,7 +581,7 @@ IPv6 可用范围非常大,以至于每台设备都可以配置一个公有 IP
581581
582582* 第二种 NAT 穿透技术*
583583
584- NAT 穿越技术拥有这样的功能 ,它能够让网络应用程序主动发现自己位于 NAT 设备之后,并且会主动获得 NAT 设备的公有 IP,并为自己建立端口映射条目,注意这些都是 NAT 设备后的应用程序自动完成的。
584+ NAT 穿透技术拥有这样的功能 ,它能够让网络应用程序主动发现自己位于 NAT 设备之后,并且会主动获得 NAT 设备的公有 IP,并为自己建立端口映射条目,注意这些都是 NAT 设备后的应用程序自动完成的。
585585
586586也就是说,在 NAT 穿透技术中,NAT 设备后的应用程序处于主动地位,它已经明确地知道 NAT 设备要修改它外发的数据包,于是它主动配合 NAT 设备的操作,主动地建立好映射,这样就不像以前由 NAT 设备来建立映射了。
587587
Original file line number Diff line number Diff line change @@ -293,7 +293,7 @@ traceroute 还有一个作用是**故意设置不分片,从而确定路径的
293293
294294这样做的目的是为了** 路径 MTU 发现** 。
295295
296- 因为有的时候我们并不知道路由器的 ` MTU ` 大小,以太网的数据链路上的 ` MTU ` 通常是 ` 1500 ` 字节,但是非以外网的 ` MTU ` 值就不一样了,所以我们要知道 ` MTU ` 的大小,从而控制发送的包大小。
296+ 因为有的时候我们并不知道路由器的 ` MTU ` 大小,以太网的数据链路上的 ` MTU ` 通常是 ` 1500 ` 字节,但是非以太网的 ` MTU ` 值就不一样了,所以我们要知道 ` MTU ` 的大小,从而控制发送的包大小。
297297
298298![ MTU 路径发现(UDP 的情况下)] ( https://cdn.jsdelivr.net/gh/xiaolincoder/ImageHost/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/ping/18.jpg )
299299
Original file line number Diff line number Diff line change 11# 5.4 怎么避免死锁?
22
3- 面试过程中,死锁也是高频的考点,因为如果线上环境真多发生了死锁 ,那真的出大事了。
3+ 面试过程中,死锁也是高频的考点,因为如果线上环境真的发生了死锁 ,那真的出大事了。
44
55这次,我们就来系统地聊聊死锁的问题。
66
Original file line number Diff line number Diff line change @@ -72,7 +72,7 @@ int pipe(int fd[2])
7272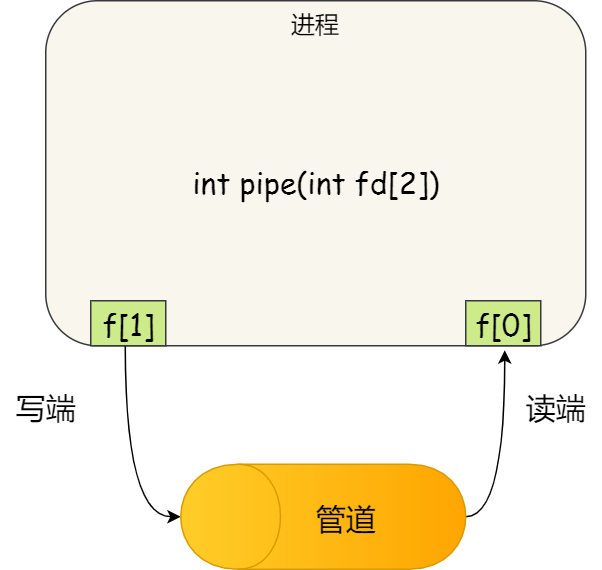
7373
7474
75- 其实,**所谓的管道,就是内核里面的一串缓存**。从管道的一段写入的数据 ,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
75+ 其实,**所谓的管道,就是内核里面的一串缓存**。从管道的一端写入的数据 ,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
7676
7777看到这,你可能会有疑问了,这两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么样才能使得管道是跨过两个进程的呢?
7878
Original file line number Diff line number Diff line change @@ -80,7 +80,7 @@ page 是内存管理分配的基本单位,Page Cache 由多个 page 构成。p
8080Linux 系统上供用户可访问的内存分为两个类型,即:
8181
8282- File-backed pages:文件备份页也就是 Page Cache 中的 page,对应于磁盘上的若干数据块;对于这些页最大的问题是脏页回盘;
83- - Anonymous pages:匿名页不对应磁盘上的任何磁盘数据块,它们是进程的运行是内存空间 (例如方法栈、局部变量表等属性);
83+ - Anonymous pages:匿名页不对应磁盘上的任何磁盘数据块,它们是进程的运行时内存空间 (例如方法栈、局部变量表等属性);
8484
8585** 为什么 Linux 不把 Page Cache 称为 block cache,这不是更好吗?**
8686
@@ -193,11 +193,11 @@ Linux 提供多种机制来保证数据一致性,但无论是单机上的内
193193
194194上述两种方式最终都依赖于系统调用,主要分为如下三种系统调用:
195195
196- | 方法 | 含义 |
197- | :---------------- | :----------------------------------------------------------- |
198- | fsync(intfd) | fsync(fd):将 fd 代表的文件的脏数据和脏元数据全部刷新至磁盘中。 |
196+ | 方法 | 含义 |
197+ | :---------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
198+ | fsync(intfd) | fsync(fd):将 fd 代表的文件的脏数据和脏元数据全部刷新至磁盘中。 |
199199| fdatasync(int fd) | fdatasync(fd):将 fd 代表的文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息 |
200- | sync() | sync():则是对系统中所有的脏的文件数据元数据刷新至磁盘中 |
200+ | sync() | sync():则是对系统中所有的脏的文件数据元数据刷新至磁盘中 |
201201
202202上述三种系统调用可以分别由用户进程与内核进程发起。下面我们研究一下内核线程的相关特性。
203203
You can’t perform that action at this time.
0 commit comments