Add Kandinsky 2.1 #3308
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,306 @@ | ||
| <!--Copyright 2023 The HuggingFace Team. All rights reserved. | ||
| Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with | ||
| the License. You may obtain a copy of the License at | ||
| http://www.apache.org/licenses/LICENSE-2.0 | ||
| Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on | ||
| an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | ||
| specific language governing permissions and limitations under the License. | ||
| --> | ||
|
|
||
| # Kandinsky | ||
|
|
||
| ## Overview | ||
|
|
||
| Kandinsky 2.1 inherits best practices from [DALL-E 2](https://arxiv.org/abs/2204.06125) and [Latent Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/latent_diffusion), while introducing some new ideas. | ||
|
|
||
| It uses [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for encoding images and text, and a diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach enhances the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation. | ||
|
|
||
| The Kandinsky model is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey) and [Denis Dimitrov](https://github.com/denndimitrov) and the original codebase can be found [here](https://github.com/ai-forever/Kandinsky-2) | ||
|
|
||
| ## Available Pipelines: | ||
|
|
||
| | Pipeline | Tasks | Colab | ||
| |---|---|:---:| | ||
| | [pipeline_kandinsky.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py) | *Text-to-Image Generation* | - | | ||
| | [pipeline_kandinsky_inpaint.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py) | *Image-Guided Image Generation* | - | | ||
| | [pipeline_kandinsky_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py) | *Image-Guided Image Generation* | - | | ||
|
|
||
| ## Usage example | ||
|
|
||
| In the following, we will walk you through some cool examples of using the Kandinsky pipelines to create some visually aesthetic artwork. | ||
|
|
||
| ### Text-to-Image Generation | ||
|
|
||
| For text-to-image generation, we need to use both [`KandinskyPriorPipeline`] and [`KandinskyPipeline`]. The first step is to encode text prompts with CLIP and then diffuse the CLIP text embeddings to CLIP image embeddings, as first proposed in [DALL-E 2](https://cdn.openai.com/papers/dall-e-2.pdf). Let's throw a fun prompt at Kandinsky to see what it comes up with :) | ||
|
|
||
| ```python | ||
| prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting" | ||
| negative_prompt = "low quality, bad quality" | ||
| ``` | ||
|
|
||
| We will pass both the `prompt` and `negative_prompt` to our prior diffusion pipeline. In contrast to other diffusion pipelines, such as Stable Diffusion, the `prompt` and `negative_prompt` shall be passed separately so that we can retrieve a CLIP image embedding for each prompt input. You can use `guidance_scale`, and `num_inference_steps` arguments to guide this process, just like how you would normally do with all other pipelines in diffusers. | ||
|
|
||
| ```python | ||
| from diffusers import KandinskyPriorPipeline | ||
| import torch | ||
|
|
||
| # create prior | ||
| pipe_prior = KandinskyPriorPipeline.from_pretrained( | ||
| "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16 | ||
| ) | ||
| pipe_prior.to("cuda") | ||
|
|
||
| generator = torch.Generator(device="cuda").manual_seed(12) | ||
| image_emb = pipe_prior( | ||
| prompt, guidance_scale=1.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt | ||
| ).images | ||
|
|
||
| zero_image_emb = pipe_prior( | ||
| negative_prompt, guidance_scale=1.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt | ||
| ).images | ||
|
Comment on lines
+53
to
+60
There was a problem hiding this comment. Consider discussing why the |
||
| ``` | ||
|
|
||
| Once we create the image embedding, we can use [`KandinskyPipeline`] to generate images. | ||
|
|
||
| ```python | ||
| from PIL import Image | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| from diffusers import KandinskyPipeline | ||
|
|
||
|
|
||
| def image_grid(imgs, rows, cols): | ||
| assert len(imgs) == rows * cols | ||
|
|
||
| w, h = imgs[0].size | ||
| grid = Image.new("RGB", size=(cols * w, rows * h)) | ||
| grid_w, grid_h = grid.size | ||
|
|
||
| for i, img in enumerate(imgs): | ||
| grid.paste(img, box=(i % cols * w, i // cols * h)) | ||
| return grid | ||
|
|
||
|
|
||
| # create diffuser pipeline | ||
| pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16) | ||
| pipe.to("cuda") | ||
|
|
||
| images = pipe( | ||
| prompt, | ||
| image_embeds=image_emb, | ||
| negative_image_embeds=zero_image_emb, | ||
| num_images_per_prompt=2, | ||
| height=768, | ||
| width=768, | ||
| num_inference_steps=100, | ||
| guidance_scale=4.0, | ||
| generator=generator, | ||
| ).images | ||
| ``` | ||
|
|
||
| One cheeseburger monster coming up! Enjoy! | ||
|
|
||
|  | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| The Kandinsky model works extremely well with creative prompts. Here is some of the amazing art that can be created using the exact same process but with different prompts. | ||
|
|
||
| ```python | ||
| prompt = "bird eye view shot of a full body woman with cyan light orange magenta makeup, digital art, long braided hair her face separated by makeup in the style of yin Yang surrealism, symmetrical face, real image, contrasting tone, pastel gradient background" | ||
| ``` | ||
|  | ||
|
|
||
| ```python | ||
| prompt = "A car exploding into colorful dust" | ||
| ``` | ||
|  | ||
|
|
||
| ```python | ||
| prompt = "editorial photography of an organic, almost liquid smoke style armchair" | ||
| ``` | ||
| 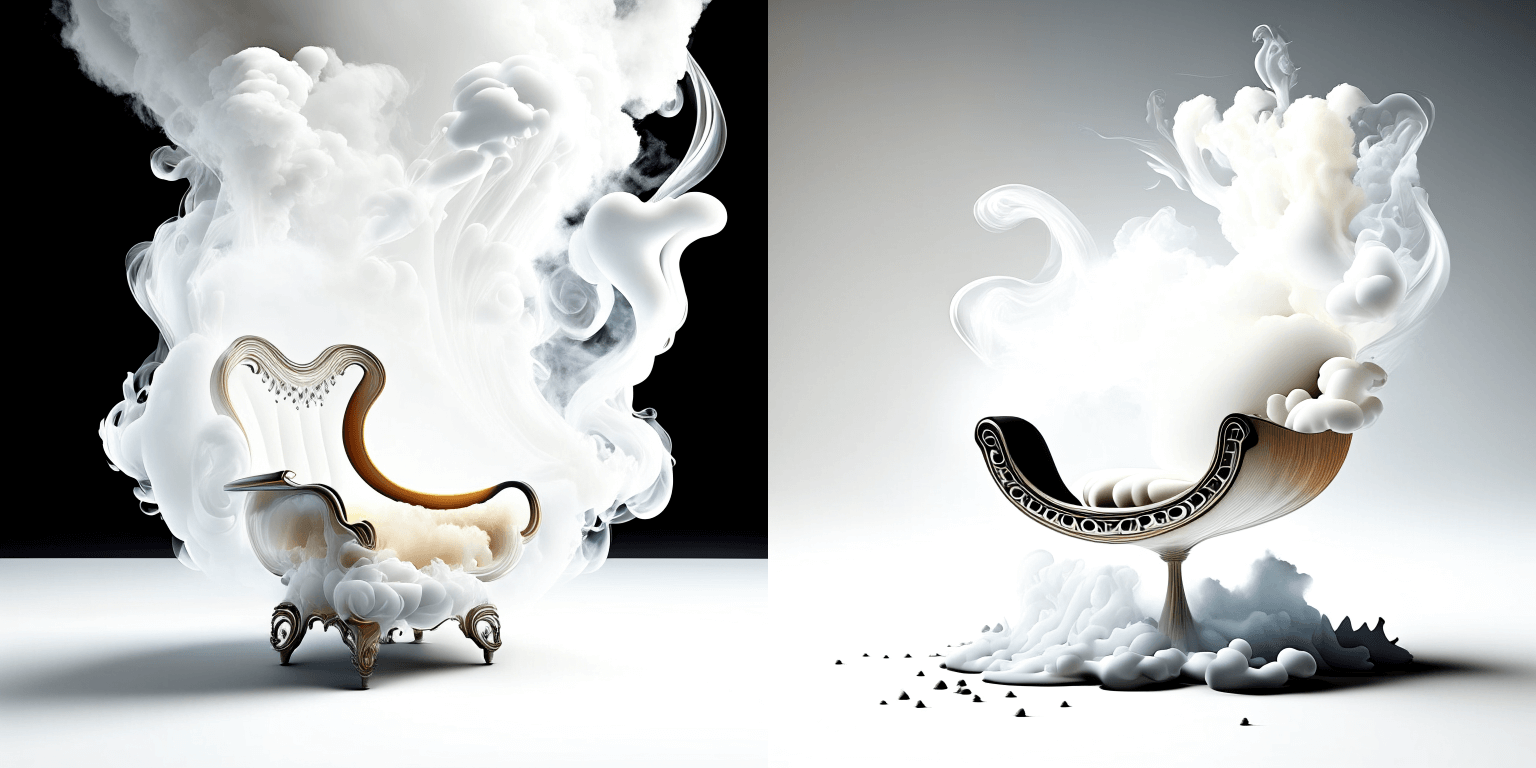 | ||
|
|
||
| ```python | ||
| prompt = "birds eye view of a quilted paper style alien planet landscape, vibrant colours, Cinematic lighting" | ||
| ``` | ||
|  | ||
|
|
||
|
There was a problem hiding this comment. If you have more examples, feel free to log them on Weights and Biases and leave a link here. Optional, though. |
||
|
|
||
| ### Text Guided Image-to-Image Generation | ||
|
|
||
| The same Kandinsky model weights can be used for text-guided image-to-image translation. In this case, just make sure to load the weights using the [`KandinskyImg2ImgPipeline`] pipeline. | ||
|
|
||
| **Note**: You can also directly move the weights of the text-to-image pipelines to the image-to-image pipelines | ||
| without loading them twice by making use of the [`~DiffusionPipeline.components`] function as explained [here](#converting-between-different-pipelines). | ||
|
|
||
| Let's download an image. | ||
|
|
||
| ```python | ||
| from PIL import Image | ||
| import requests | ||
| from io import BytesIO | ||
|
|
||
| # download image | ||
| url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg" | ||
| response = requests.get(url) | ||
| original_image = Image.open(BytesIO(response.content)).convert("RGB") | ||
| original_image = original_image.resize((768, 512)) | ||
| ``` | ||
|
|
||
|  | ||
|
|
||
| ```python | ||
| import torch | ||
| from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline | ||
|
|
||
| # create prior | ||
| pipe_prior = KandinskyPriorPipeline.from_pretrained( | ||
| "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16 | ||
| ) | ||
| pipe_prior.to("cuda") | ||
|
|
||
| # create img2img pipeline | ||
| pipe = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16) | ||
| pipe.to("cuda") | ||
|
|
||
| prompt = "A fantasy landscape, Cinematic lighting" | ||
| negative_prompt = "low quality, bad quality" | ||
|
|
||
| generator = torch.Generator(device="cuda").manual_seed(30) | ||
| image_emb = pipe_prior( | ||
| prompt, guidance_scale=4.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt | ||
| ).images | ||
|
|
||
| zero_image_emb = pipe_prior( | ||
| negative_prompt, guidance_scale=4.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt | ||
| ).images | ||
|
|
||
| out = pipe( | ||
| prompt, | ||
| image=original_image, | ||
| image_embeds=image_emb, | ||
| negative_image_embeds=zero_image_emb, | ||
| height=768, | ||
| width=768, | ||
| num_inference_steps=500, | ||
| strength=0.3, | ||
| ) | ||
|
|
||
| out.images[0].save("fantasy_land.png") | ||
| ``` | ||
|
|
||
|  | ||
|
|
||
|
|
||
| ### Text Guided Inpainting Generation | ||
|
|
||
| You can use [`KandinskyInpaintPipeline`] to edit images. In this example, we will add a hat to the portrait of a cat. | ||
|
|
||
| ```python | ||
| from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline | ||
| from diffusers.utils import load_image | ||
| import torch | ||
| import numpy as np | ||
|
|
||
| pipe_prior = KandinskyPriorPipeline.from_pretrained( | ||
| "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16 | ||
| ) | ||
| pipe_prior.to("cuda") | ||
|
|
||
| prompt = "a hat" | ||
| image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False) | ||
|
|
||
| pipe = KandinskyInpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16) | ||
| pipe.to("cuda") | ||
|
|
||
| init_image = load_image( | ||
| "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png" | ||
| ) | ||
|
|
||
| mask = np.ones((768, 768), dtype=np.float32) | ||
| # Let's mask out an area above the cat's head | ||
| mask[:250, 250:-250] = 0 | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| out = pipe( | ||
| prompt, | ||
| image=init_image, | ||
| mask_image=mask, | ||
| image_embeds=image_emb, | ||
| negative_image_embeds=zero_image_emb, | ||
| height=768, | ||
| width=768, | ||
| num_inference_steps=150, | ||
| ) | ||
|
|
||
| image = out.images[0] | ||
| image.save("cat_with_hat.png") | ||
| ``` | ||
|  | ||
|
|
||
| ### Interpolate | ||
|
|
||
| The [`KandinskyPriorPipeline`] also comes with a cool utility function that will allow you to interpolate the latent space of different images and texts super easily. Here is an example of how you can create an Impressionist-style portrait for your pet based on "The Starry Night". | ||
|
|
||
| Note that you can interpolate between texts and images - in the below example, we passed a text prompt "a cat" and two images to the `interplate` function, along with a `weights` variable containing the corresponding weights for each condition we interplate. | ||
|
|
||
| ```python | ||
| from diffusers import KandinskyPriorPipeline, KandinskyPipeline | ||
| from diffusers.utils import load_image | ||
| import PIL | ||
|
|
||
| import torch | ||
| from torchvision import transforms | ||
|
|
||
| pipe_prior = KandinskyPriorPipeline.from_pretrained( | ||
| "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16 | ||
| ) | ||
| pipe_prior.to("cuda") | ||
|
|
||
| img1 = load_image( | ||
| "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png" | ||
| ) | ||
|
|
||
| img2 = load_image( | ||
| "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg" | ||
| ) | ||
|
|
||
| # add all the conditions we want to interpolate, can be either text or image | ||
| images_texts = ["a cat", img1, img2] | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| # specify the weights for each condition in images_texts | ||
| weights = [0.3, 0.3, 0.4] | ||
| image_emb, zero_image_emb = pipe_prior.interpolate(images_texts, weights) | ||
|
|
||
| pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16) | ||
| pipe.to("cuda") | ||
|
|
||
| image = pipe( | ||
| "", image_embeds=image_emb, negative_image_embeds=zero_image_emb, height=768, width=768, num_inference_steps=150 | ||
| ).images[0] | ||
|
|
||
| image.save("starry_cat.png") | ||
| ``` | ||
|  | ||
|
|
||
|
|
||
| ## KandinskyPriorPipeline | ||
|
|
||
| [[autodoc]] KandinskyPriorPipeline | ||
| - all | ||
| - __call__ | ||
| - interpolate | ||
|
|
||
| ## KandinskyPipeline | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| [[autodoc]] KandinskyPipeline | ||
| - all | ||
| - __call__ | ||
|
|
||
| ## KandinskyInpaintPipeline | ||
|
|
||
| [[autodoc]] KandinskyInpaintPipeline | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| - all | ||
| - __call__ | ||
yiyixuxu marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| ## KandinskyImg2ImgPipeline | ||
|
|
||
| [[autodoc]] KandinskyImg2ImgPipeline | ||
| - all | ||
| - __call__ | ||
|
|
||
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.